The dependency inversion principle, postulated by Robert C. Martin, is perhaps the most important object-oriented design principle. It was this principle that fundamentally transformed how I think about application architecture, and it is this principle that enables modularity, fast build times, and test-driven development in large-scale projects, all while promoting clarity and reusability.
The dependency inversion principle (DIP) is the “D” in the SOLID design principles. It states:
- High-level modules should not import anything from low-level modules. Instead, both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
What does this mean? First of all, try not to get caught up on terminology, the principle is described fairly abstractly, and that’s on purpose. As with all design principles, they are intended to be applied universally across tech stacks, and they are language-agnostic. The principle is about organizing code and ideas in a flexible and easy to understand manner.
Breaking it Down
Module: All this means is some unit of code. Whether it’s a function, class, file, namespace, or package, it doesn’t matter, because the principle applies equally to any of these.
High-Level & Low-Level: Here we are thinking about the level of detail. High-level modules are those closely related to the problem domain or application requirements. Low-level modules are those concerned with implementation details. The high-level modules are written more abstractly than low-level modules. They are not concerned with how the application requirements are met, but that they are. On the other hand, low-level modules do not know how they will be orchestrated to solve a problem and deliver value to stakeholders. Instead, they are focused only on their piece of the puzzle. Low-level modules are concerned with specific protocols or transmission methods, types of persistence, and user interface details.
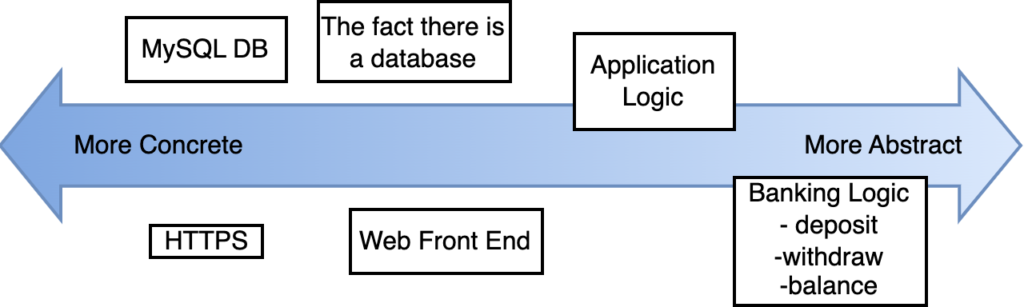
In Robert C. Martin’s Clean Architecture, he talks about how the database is a detail. And along the same sentiment, so is the user interface. These kinds of components are necessary to provide actual value to stakeholders, but the fact there is a database (instead of in-memory persistence) or the fact that there is a web front end (instead of a command-line interface) are design decisions that are somewhat arbitrary. By differentiating high-level and low-level concerns, we can increase the flexibility of our architecture.
Import: This word could be defined technically. Literally, to create a compile-time link between modules. However, I believe it is better to define it more loosely. I prefer to think of import as “incorporate the knowledge of”. Defined this way, dependency inversion principle requires that high-level components have no knowledge of the inner workings of low-level components. This includes the inner logic, but I’d go so far as to say that even ideas introduced in comments should not be borrowed in high-level components. The same applies to naming things. You may know your system has a database, or you may even know if you are using MySQL or MongoDB, but your high-level code shouldn’t reference these ideas anywhere. Instead, you should use an abstraction, such as a repository, and reference that instead.
Abstractions: These are the interfaces that loosely join the high-level and low-level modules. Because high-level modules shouldn’t know about the inner workings of low-level modules, an abstraction (such as a service, repository, or presenter) is defined and the high-level modules depend on it to carry out the actual work in a detail-agnostic manner.
In the beginning, I mentioned that dependency inversion principle promotes clarity. The reason for this clarity is that by applying the dependency inversion principle, you necessarily separate concerns, and approach a single level of abstraction, another design principle promoted in Uncle Bob’s Clean Code. When your high-level and low-level concerns aren’t mixed, it is easier to reason with the code. So, when a module needs to incorporate logic from another layer, it should use an interface and retain a single level of abstraction.
Putting it all Together
To restate the principle, high-level modules should not depend on low-level modules, they should both instead depend on abstractions. And abstractions should not depend on details, but details should depend on abstractions. From the first point, we get a separation of high and low level concerns, and they only should interact through some kind of interface. The second point tells us where this interface should live, which is important since it tells us where dependencies flow, or how our modules may be built and linked. Specifically, the abstraction must live at the same layer (or higher) than the depending high-level module. This is best demonstrated with a diagram. Instead of this:
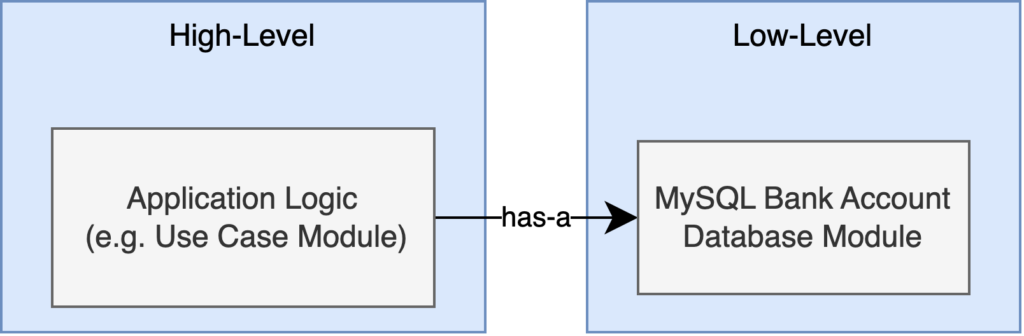
Dependencies are inverted by introducing an abstraction layer:
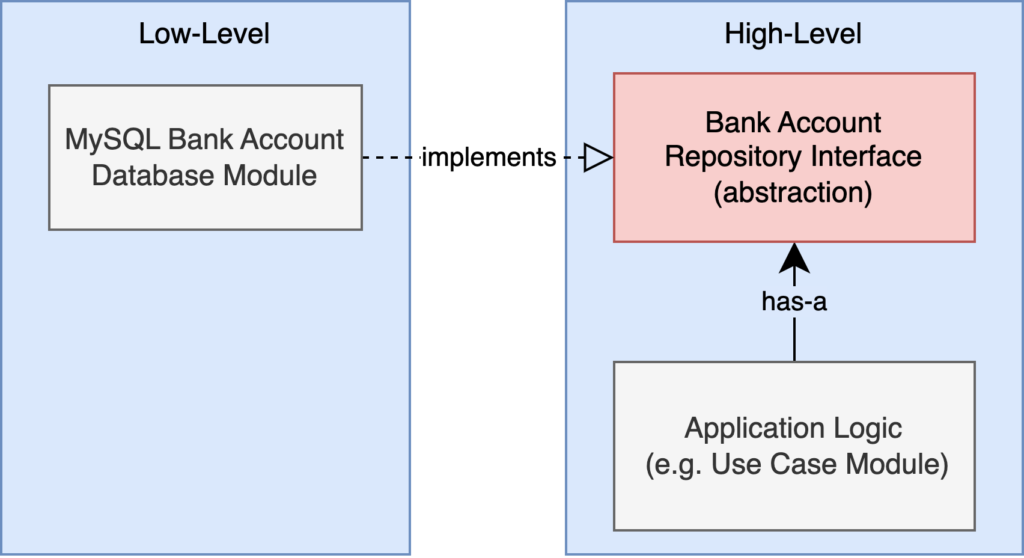
In the diagram, the database module contains MySQL-specific logic. It knows how to create queries, it understands the concerns of a relational-database or object-relational mapping, and there are references to MySQL library calls. This module implements the bank account repository interface.
The repository interface, whose exact design is likely dictated by a set of user stories, just contains basic create/read/update/delete (CRUD) operations. It is written using high-level terminology, agnostic to any particular implementation details. This will grant us the flexibility to swap out the MySQL implementation for an alternative persistence solution while leaving the rest of the system in-tact. And this should be a relatively straightforward change; after all, there are no dependencies pointing to the MySQL module.
Finally, the application logic, perhaps in the form of a use case class, is written to orchestrate various components in the system and is responsible for enforcing business rules such as returning an error when trying to withdraw more than the available balance. Or, if that is a valid scenario, let the balance go negative and start tracking interest. The application logic also has a dependency on the repository, and uses it to accomplish the lower-level concern of persisting any changes to the bank account without caring how it is done.
Final Thoughts
We’ve discussed what the dependency principle is and some of the reasons why it’s useful, but I wanted to connect it back to what I said originally. It transformed the way I thought about application architecture, and when I understood how to apply it in large codebases, I learned how to refactor tightly-coupled features into easily testable units.
In one app I’ve worked on, features were part of the main project. We wanted to incorporate these features into the app, but we also wanted them to be tested rapidly. Testing these features required building the entire app, including all of the other features that we weren’t interested in. To solve this issue, we began by creating or extracting feature interfaces that the main project could depend on. Then, we relocated the feature code into a separately compilable modules, and implemented the interfaces. We now had a separation of concerns connected in a loosely-coupled manner via abstractions. Sound like dependency inversion principle yet?
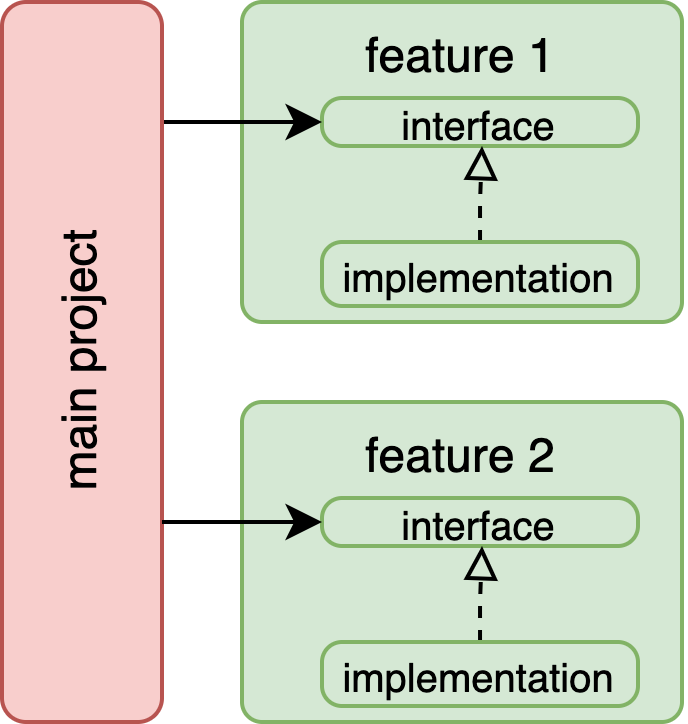
Often, we ran into issues. What if our now half-refactored feature depended on a core service or another feature? Easy, apply dependency inversion principle again. Create another abstraction, change the service to implement it, and rewire our feature to depend on the abstraction rather than the concrete service class. Where do abstractions get created? It depends on how we want our module dependencies to be set up. We could create a feature to feature dependency, or we could move abstractions to their own module, separate from implementations. Here are a couple examples:
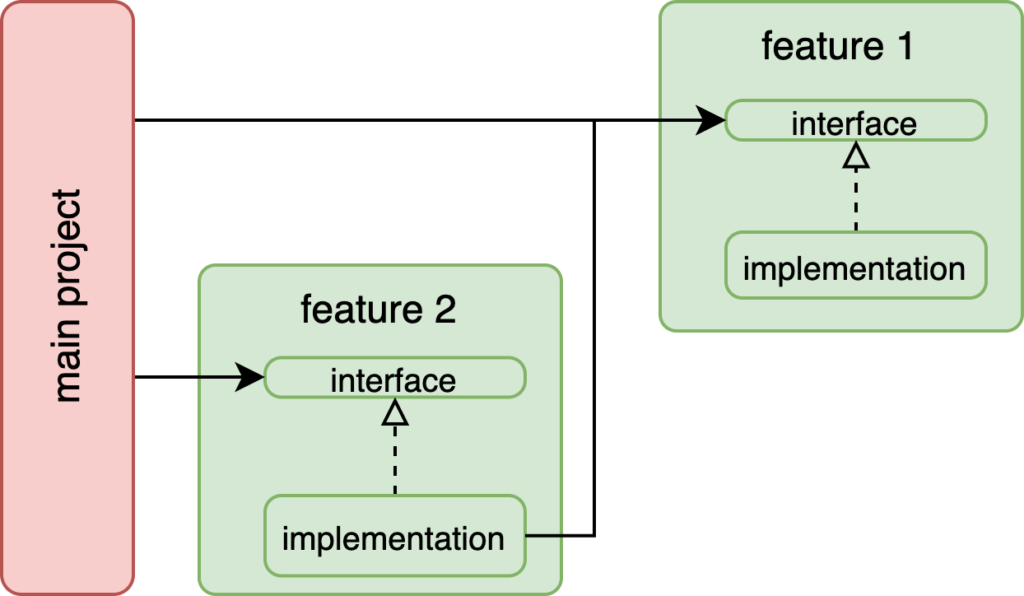
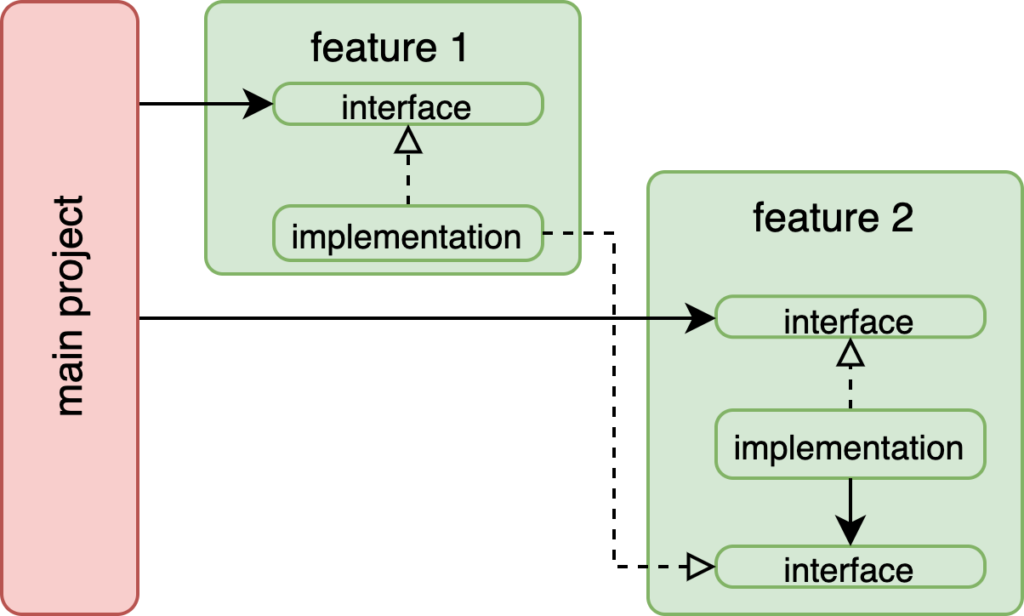
These setups are almost identical. The major difference is that on the left, feature 2 depends on feature 1, and on the right, it’s the reverse. Also on the right, the feature 1’s interface is not reused. Although feature 1 doesn’t change in behavior, we can reorient the direction of the dependency by defining another interface in feature 2. This is an example of applying the interface segregation principle.
In our app, the main project (which was the outermost layer) used an inversion of control container to associate interfaces with their implementations. Then, when instantiating our feature modules, any dependencies were injected by the container. The basic rule we followed was that a feature must never depend on the another feature or the main project directly. If a dependency was needed, we had to create an abstraction and invert the dependency.
After all of the feature code was in separate modules and there were no dependencies to the rest of the project, we could easily invoke our unit tests. Instead of waiting 5 minutes per build, we brought it down to seconds. And that was imperative if we were going to practice test-driven development! TDD requires you to constantly cycle through creating failing tests, changing production logic to satisfy those tests, then refactoring (and checking that all tests still pass). With only a few seconds per build, we now had rapid feedback and could practice TDD productively.
In closing, dependency inversion principle gives you full control over your application’s architecture. You get to decide how you want to organize your modules, and you can progressively adopt a new architecture by introducing abstractions. You get to decide when the flow of control runs along with your module’s dependencies, or you can invert the dependencies to go against the flow of control.
Leave a Reply